On Nov 2-3 the autumn 2011
euroCRIS membership meeting was held at the University of Lille 3 in Lille, France. Attendees from 14 countries (13 European nations plus Canada) met for two days at the Univ-Lille3 Maison de Recherche for learning about the
new CERIF 1.3 version (to be released Dec 2011) and the growing number of CERIF-based CRIS implementations in Europe, with a special focus on French ones (see
event programme).
Brigitte Joerg, euroCRIS CERIF Task Group Leader and German Research Center for Artificial Intelligence (DFKI), delivered a
CERIF v1.3 tutorial at the beginning of the membership meeting. After a general-purpose introduction to CERIF, CRIS Systems and the euroCRIS Group for first-time meeting attendees, the tutorial went into describing new features in the new CERIF 1.3 release (CERIF versions will no longer be named by their year of release as they were so far). Such features include the so-called
Infrastructure entities (Facility, Equipment, Service) that have been added to the already existing CERIF Entity Types, namely
Base entities (Project, Person, Organisational Unit),
Result entities (ResultPublication, ResultPatent, ResultProduct),
Second Level entities and
Link entities.

Furthermore, the JISC RIM2
MICE Project outcomes (Measuring Impact Under CERIF) have also been brought into the CECRIF 1.3 release under the Measurement & Indicator section. MICE was one of the RIM2 projects –together with CERIFy, BRUCE and IRIOS- presented last September at the JISC
programme workshop in Manchester. MICE finished on July 2011 and aimed to “examine the potential for encoding systematic and structured information on research impact in the context of the CERIF schema. MICE aims to build on previous work on impact by producing a comprehensive set of indicators which will then be mapped both to the CERIF standard and the CERIF4REF schema created by the previous Readiness for REF (R4R) Project”. MICE-inspired CERIF 1.3 updates include creation of a new CERIF table, namely the impact measure table, as well as a set of impact indicators: categories that include such concepts as
improving performance of existing businesses,
improved health outcomes and
cultural enrichment. euroCRIS was also involved in the RIM2 UKOLN-led
CERIFy Project, dealing with measures of esteem, whose results were as well inspiring for CERIF new Measurement & Indicator definition.
Another new feature for this CERIF release is the
Geographic bounding boxes, which will allow displayed information to be restricted to a given geographic area. Geographic bounding boxes are presently defined as squares, thus leaving room for geolocation improvement in future CERIF versions. Finally, a new Linked Open Data (LOD) CERIF Task Group is being planned by euroCRIS.
As a result from this new features, changes in CERIF 1.3 release include a whole set of new entities (such as cfMedium as a new Document Type) and new attributes, as well as removal of some other outdated attributes. The new CERIF version described at the tutorial was a preview, with features such as XML Data Exchange Format Specification and CERIF Formal Semantics still being worked upon until 1.3 version gets finally released next December.
An euroCRIS Overview Session followed the CERIF Tutorial, along which different members of euroCRIS Board reported recent activity. Keith Jeffery highlighted the
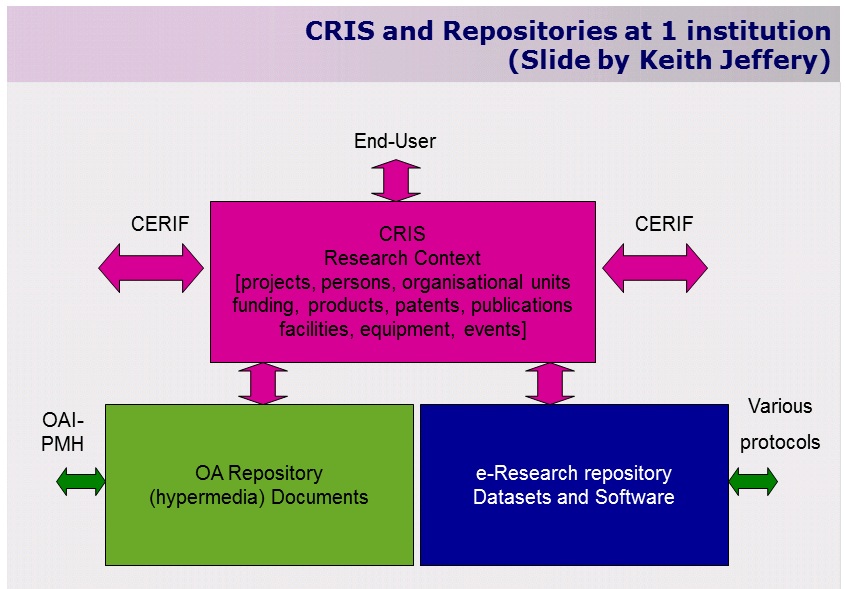
euroCRIS Rome Declaration on CRIS/IR integration issued earlier this year and mentioned that while CERIF can generate multiple metadata standards such as DC, MODS, etc, OAR usual qDC-based metadata model was insufficiently accurate, so some integration should be seeked along the model CRIS-Publications OAR-Data/Software OAR.

Other euroCRIS-related activity includes EU FP7
OpenAIRE Project moving from qDC to some semi-CERIF standard, as well as the fact that
OpenAIRE+ Project will use CERIF. By definition, CERIF serves a multiple-institution scheme (thus allowing for wider context-related information sharing for purposes such as the Research Excellence Framework assessment in the UK), so there’s also a clear need to operate internationally as to demonstrate CERIF interoperability capabilities.
Harry Lalieu, euroCRIS Secretary, announced
CRIS2012 Conference to be held in Prague next June, and 2012 euroCRIS membership meetings, which will tale place in Prague just before the CRIS2012 event and possibly in Spain later next year.
Anne Asserson, Universitetet i Bergen and responsable for euroCRIS strategy, announced dataset management as the next environment CERIF will be next moving into (with projects such as University of Sunderland-led
CERIF for Datasets paving the way for such move).
Speaking on behalf of Ed Simons, Universiteit Nijmegen and euroCRIS website manager, Keith Jeffery informed the audience a test CRIS is being planned for inclusion at the euroCRIS site, thus allowing for future live-demoing and functionality analysis.
Within the euroCRIS Task Group reports, Brigitte Joerg mentioned the euroCRIS Board-authored paper “
Towards a Sharable Research Vocabulary (SRV) - A Model-driven Approach” having been presented at the Metadata and Semantics Research Conference (
MTSR 2011) held last October in Izmir, Turkey. A preliminary meeting with Virtual Open Access Agriculture & Aquaculture Repository (
VOA3R) Project was also recently held in Madrid in order to plan the future euroCRIS Linked Open Data (LOD) Task Group.
Nikos Houssos, NDC Athens and Task Group Projects leader mentioned running EC FP7 Projects euroCRIS is involved into, such as
ENGAGE, dealing with Open Access to Public Sector Information,
EuroRIs-Net, one of whose outputs is providing an online CERIF database of RI stakeholders, and OpenAIRE+. UK/JISC Projects such as CERIFy, CRISPool, BRUCE, IRIOS, MICE or RMAS were also cited as a proof of CERIF gradually becoming a common standard for RIM Programme Projects. Many of those projects are having an active euroCRIS involvement.
Danica Zendulková,
CVTISR and CRIS-IR Interoperability Task Group leader, announced upcoming TG work along lines such as defining usecases for CRIS/IR interoperability, defining a model of integration interface (including XML data exchanges and web services), implementng an authority file model with attached persistent ID and promoting cooperation between CRIS/OAR communities.
Finally, David Baker,
CASRAI and euroCRIS Architecture Task Group manager explained the way towards the Reference CRIS implementation. According to implementation plans, a test CRIS should be available at the euroCRIS site on June 2012.
Several sessions –see
euroCRIS meeting presentations- followed the euroCRIS Overview, summarizing recent and forthcoming developments in CRIS and CERIF implementation. An interesting discussion was also held, led by Joachim Schöpfel, on teaching CRIS Systems to his
Information Science students at Université de Lille and on potential CERIF application to the teaching environment and scholarly activities beyond research.
A particularly relevant presentation –as it described CERIF-based CRIS implementation in the UK, where CERIF standard adoption has been most successful so far– was UKOLN Rosemary Russell’s
“CERIF UK landscape” (final report to be formally published later this year by UKOLN-University of Bath). Some figures were mentioned at the presentation: 17 PURE/Atira CERIF-based CRIS were implemented in the UK along last year, plus 5 Converis/Avedas CRISes and a large number of Symplectic Elements.

The CERIF UK Landscape Project carried out a set of seven interviews among ‘CRIS Project managers’ from different institutions - based at the institutional Research Office (2), Library/Info Services (4) or IT Department (1)- in order to gather their views on the implementation process, CRIS reception by end-users (researchers) and staff, plus experience on CERIF and integration with Institutional Repositories. A summary of the –often not so encouraging– answers is available at the presentation, CERIF being perceived by many as a far too complicated standard whose management would rather be handed over to the CRIS commercial provider. It is a fact however that institutions running a CERIF-based CRIS are in a much better position to deal with the REF requirements.